
Análise de dados sobre produção de leite: uma perspectiva da Ciência da Informação
• Resumo • Introdução • Métodos • Resultados • Informações para uso dos dados • Informações Adicionais • Referências • Citação dos Dados • Informações sobre os Autores • Informações Complementares
A coleta e tratamento de dados sobre a atividade agrícola, apesar de sua importância, ainda encontra-se distante de atingir todo seu potencial. A Ciência da Informação pode contribuir desenvolvendo estudos e pesquisas sobre processos e fatores envolvidos no ciclo de vida dos dados propiciando a ampliação da democratização do uso dos dados, viabilizando a mediação no acesso a estes conhecimentos. A atividade pecuária de produção de leite, de forte relevância social e econômica pode receber aportes em seu processo de planejamento por meio de análise de dados já disponíveis na Internet. Neste estudo são apresentados resultados de análises sobre o cruzamento de dados sobre o número de animais em ordenha e a localização geográfica de cidades, apresentando uma visualização de coeficientes de correlação que podem contribuir com estratégias empresariais e ampliando o suporte, aplicação e acompanhamento de políticas públicas.
Palavras-Chave: Análise de dados. Produção de Leite. Coeficiente de correlação.
Data Analysis on milk production: an Information Science perspective
Abstract
Collection and processing of data on agricultural activity, besides its importance, is still far from reaching full potential. Information Science can contribute developing studies and researches about processes and factors involved in the Data Life Cycle fostering expanded democratization of the use of the data, enabling the mediation access to this knowledge. The milk production, with a strong social and economic relevance, can receive contributions in their planning process by analyzing data already available on the Internet. In this study results of analysis on the intersection of data on the number of animals in milking and geographical location of cities are presented, showing a preview of correlation coefficients that can contribute to business strategies and expanding the support and accounting of public policy.
Keywords: Data Analytics. Milk Production. Correlation Coefficient.
• Resumo • Introdução • Métodos • Resultados • Informações para uso dos dados • Informações Adicionais • Referências • Citação dos Dados • Informações sobre os Autores • Informações Complementares
A profunda penetração das tecnologias digitais de informação e comunicação nas mais diversas dimensões do tecido social (CASTELLS, 1999) proporciona um cenário cheio de oportunidades para construção de ambientes menos assimétricos nas relações entre seus atores.
Esta maior simetria pode ser obtida por meio da efetiva ampliação do acesso e interpretação do que vem sendo identificado como ‘Big Data’ e que representa o potencial de uso de grandes volumes de dados, em formatos variados e que passam a estar acessíveis em processos velozes o suficiente para que tenham tempestividade suficiente para garantir sua relevância. No entanto este acesso implica em utilização de recursos tecnológicos, que ainda exigem conhecimentos específicos sobre práticas que abrangem domínios variados.
Na busca pela redução da assimetria informacional (AKERLOF,1970) o acesso a estes recursos precisa ser amplo e democrático. Assim, é preciso criar condições para seu entendimento, principalmente por meio da apresentação de suas vantagens e tornando a busca por sua utilização mais atrativa para todos os setores da sociedade.
A Ciência da Informação, por meio do estudo e identificação dos processos e fatores envolvidos no ciclo de vida dos dados (Figura 1), pode contribuir com este processo de democratização do uso dos dados, estruturando tanto a produção científica sobre o tema como contribuindo para divulgação no contexto científico e em âmbito mais amplo, viabilizando a mediação no acesso a estes conhecimentos.
Figura 1. Ciclo de Vida dos Dados
Fonte: Sant’Ana, 2013
Neste artigo, apresenta-se um processo de acesso, uso, interpretação e disponibilização de dados sobre a pecuária de leite no intuito de fomentar a reflexão não só sobre os resultados encontrados mas, principalmente, sobre o processo em si. No tópico métodos são apresentadas as fases do ciclo de vida dos dados abordadas nesta pesquisa.
Pecuária de Leite
A atividade rural exige planejamento e envolve alto grau de risco, apresentando fatores complicadores neste processo de planejamento, “[...] no contexto agrícola a coleta de dados é muito mais complicada, em parte em função da natureza aberta dos sistemas das atividades, em que os processos são mais diversificados e multifacetados que em outros setores como o industrial” (LEWIS et al, 1999) acrescentando-se, ainda, que apresentam forte influência de fatores externos incontroláveis, tais como solo, condições climáticas e pragas.
A escolha do objeto deste estudo, “[...] sistemas de produção de leite com base em rebanhos comerciais, a principal fonte de receita é a venda do leite” (CARDOSO et al., 2004) por suas características, tais como ser produto perecível, suscetível a condições climáticas, qualidade de rebanhos, e também, de forma bastante sensível, a localização geográfica do ambiente de produção.
O objetivo da análise de dados apresentada neste trabalho, tem como foco a busca por alternativas de tratamento e uso de bases de dados, já disponíveis na Internet, para que se possa obter informações que auxiliem e complementem estratégias de melhoria da competitividade subsidiando estratégias empresariais e ampliando o suporte, aplicação e acompanhamento de políticas públicas, possibilitando, ainda, a definição de estratégias de uso de dados para delimitação de sistemas agroindustriais.
Considerando que este importante setor pode estar sujeito a fatores como as condições edafoclimáticas, culturais (disponibilidade de mão de obra preparada), logísticas e de volume regional de produção. Este último fator é chave na identificação da influência da variável localização já que a proximidade com grandes compradores é valorizada pela necessidade destes de estabelecer uma carteira de fornecedores que ofereçam grandes volumes diários de e que apresentem pequena variação sazonal da produção (FONSECA, 2001).
• Resumo • Introdução • Métodos • Resultados • Informações para uso dos dados • Informações Adicionais • Referências • Citação dos Dados • Informações sobre os Autores • Informações Complementares
A análise realizada neste artigo tomou como base duas principais variáveis: a localização geográfica e o número de animais em ordenha no ano de 2007 (IPEA,2014).
Contextualiza-se a seguir o estudo realizado com base no ciclo de vida dos dados (SANT’ANA, 2013).
Fase de Coleta
Na fase de coleta houve a identificação dos dados necessários para a análise que teve como base a localização geográfica e um indicador de produção. A localização geográfica se baseou em coordenadas (longitude e latitude). Já para o indicador de produção, buscou-se por uma variável quantitativa que não sofresse influência direta do valor de comercialização do produto ou de variações climáticas que poderiam distorcer os resultados em função da vinculação com o tempo vinculado aos dados obtidos, assim, optou-se pelo número de animais em produção.
A obtenção dos dados foi realizada no sítio de dados na Internet do Instituto de Pesquisa Econômica Aplicada Ipea (IPEA, 2014) que oferece a opção de download dos dados em planilha no formato XLS.
Como delimitação do escopo da coleta, para viabilizar a elaboração de gráficos e de análises de correlação, foi definido o Estado de São Paulo por ser o estado de origem da instituição que os autores estão vinculados.
Os dados obtidos foram tratados com o cálculo de distância com elaboração de matriz de distância entre todas as cidades com base na fórmula (1):
Distância = R * acos (sin (LatA) * sin (LatB) + cos (LatA) * cos (LatB) * cos (LonA-LonB)) (1)
Sendo: R o raio aproximado (6372.795477598), LatA, LatB, LonA e LonB latitudes e longitudes das cidades A e B em radianos.
A partir das distâncias e do número de animais em produção buscou-se identificar a área de influência de centros de produção sobre localidades com volume menor de animais em produção, baseando-se na identificação de correlação entre a localização geográfica e os respectivos pesos representados pelo número de animais, considerando-se esta área de influencia em função, portanto, da distância e do potencial de produção por meio de algoritmo hierárquico. Utilizou-se como fator limitante de possibilidade de influência direta a distância de 40 quilômetros, que puderam ser superados em função da possibilidade de influência indireta por meio de outra localidade entre a cidade analisada e um centro maior. A definição do limite de 40 quilômetros se deu a partir de ensaios realizados com valores gerando os resultados apresentados no quadro 1.
Quadro 1. Ensaios com diferentes limites de distância.

Fonte:
Autores
* Número de elementos do grupo.
A partir da identificação dos centróides foram calculados os coeficientes de correlação de Karl Pearson e de Spearman entre as variáveis: Peso do Grupo, que representa a soma dos animais em produção no grupo; Peso do Centróide com o número de animais em produção; Diâmetro do Grupo que identifica a maior distancia entre um centróide e os elementos do seu grupo; Distância da Capital, referente a distância entre o centróide e a capital do estado,e ; Numero de Elementos que apresenta o número de cidades identificadas em cada grupo.
Com relação a questão da privacidade não houve nenhuma ação necessária para higienizar os dados já que em sua origem já se tratava de dados sumarizados que representam em sua essência a posição geográfica de cidades e o número total de animais em produção, portanto, sem nenhuma possibilidade de engenharia reversa ou de efeito mosaico (CONESA, 1984) na base utilizada ou produzida no estudo. Com relação a integração, o processo foi facilitado por ser baseado em apenas uma fonte de dados e a integração com a base de dados gerada foi possível graças a inclusão de um atributo, sequencial numérico, para cada cidade e que foi adotado como chave primária de cada tupla o que norteou todo o processamento realizado. A qualidade dos dados utilizados é lastreada pela própria origem da fonte de dados utilizada (IPEA, 2014), o que também facilitou a garantia de que não foram infringidos os direitos autorais dos responsáveis pela base de dados utilizada, que em seu sítio deixam claro a possibilidade de uso dos dados desde que citada a fonte:
“O propósito deste site é facilitar o acesso às estatísticas brasileiras e promover a divulgação dos estudos e pesquisas do Ipea. Este site é disponibilizado como uma prestação pública de serviço pelo Ipea e seu conteúdo é considerado informação pública que pode ser livremente distribuída e copiada, resguardando-se a obrigatoriedade de citação da fonte Ipeadata por parte do usuário.”(IPEA, 2014)
Com o proposito de facilitar a disseminação do conteúdo gerado nesta pesquisa, foram incluídos nos dados disponibilizados (SANT'ANA & BONINI NETO, 2014) os atributos código e nome da cidade, que mesmo não tendo sido utilizados diretamente nos processamentos relacionados a esta pesquisa podem facilitar o reuso destes dados. A preservação dos dados gerados foi garantida pelo próprio envio, junto ao texto resultado, de arquivo em formato csv, e que, portanto, não depende de aplicação específica. Também contribui para este fim a documentação disponibilizada neste texto e o uso da primeira linha do arquivo de dados para registro dos metadados de identificação de cada um dos atributos que compõem o arquivo.
Fase de Armazenamento
Para que os dados obtidos possam ficar disponíveis para acesso, adotou-se o formato de dados aberto, separados por virgula (CSV), e disponibilizados junto ao artigo conforme tópico Informações para uso dos dados.
Análise de Correlação
Adotou-se neste trabalho, como forma de análise de possíveis correlações entre as variáveis tratadas os parâmetros propostos por Karl Pearson (STANTON, 2001; PAGANO & GAUVRO, 2012),sendo obtida pela fórmula (2):

Sendo que o resultado obtido pode ser interpretado por meio dos seguintes parâmetros:
0,7 <= r < 1 -> correlação linear fortemente positiva.
0,3 <= r < 0,7 -> correlação linear moderada positiva.
0 <= r < 0,3 -> correlação linear fraca positiva.
r = 0 -> não existe correlação linear.
-1 <= r < -0,7 -> correlação linear fortemente negativa.
-0,7 <= r < -0,3 -> correlação linear moderada negativa.
-0,3 <= r < 0 -> correlação linear fraca negativa.
A análise correlacional indica a relação entre 2 variáveis lineares e os valores sempre serão entre +1 e -1. O sinal indica a direção, se a correlação é positiva ou negativa, e o tamanho da variável indica a força da correlação.
Aplicou-se, ainda, outra análise não paramétrica de correlação baseada em processo de comparação de postos, que se obtém ao ordenar os elementos que compõem os dois conjuntos de valores em análise, calculando-se então um coeficiente conhecido como coeficiente de correlação de Spearman (PAGANO & GAUVREAU, 2012).
• Resumo • Introdução • Métodos • Resultados • Informações para uso dos dados • Informações Adicionais • Referências • Citação dos Dados • Informações sobre os Autores • Informações Complementares
Os dados sobre as cidades e suas coordenadas obtidos no sítio do Ipeadata (IPEA, 2014), o que permitiu a contextualização das cidades em função de sua localização conforme figuras 2 e 3. O sítio do Ipea disponibiliza interface Web que permite a elaboração dos resultados por tema e período o que propiciou a coleta dos dados analisados neste estudo.
Figura 2. Visualização das coordenadas das cidades brasileiras
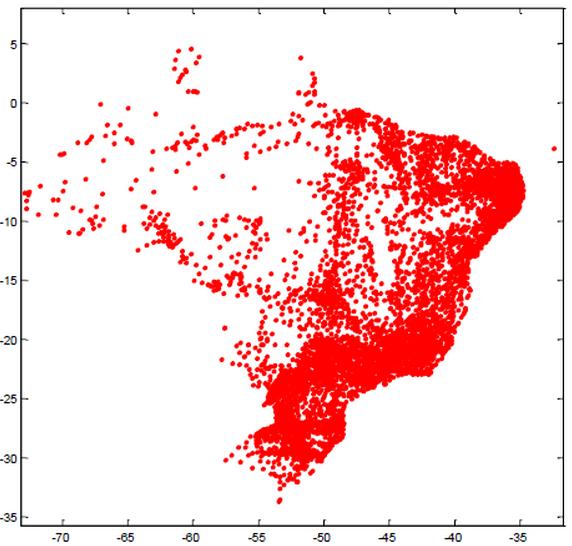
Fonte:
Autores.
Figura 3. Visualização das coordenadas das cidades do Estado de São Paulo.

Fonte:
Autores.
Identificação dos grupos
Em função da localização e do número de animais em produção obteve-se a seguinte distribuição de grupos de cidades, considerando-se os centros as cidades com maior peso e como limite de análise para divisão dos grupos a distância limite de 40 quilômetros, conforme descrito no tópico métodos. A figura 4 apresenta estes grupos, destacando em verde as cidades, os círculos os centróides e os pontos em vermelho as cidades sem registro de animais em produção.
Figura 4. Grupos identificados.
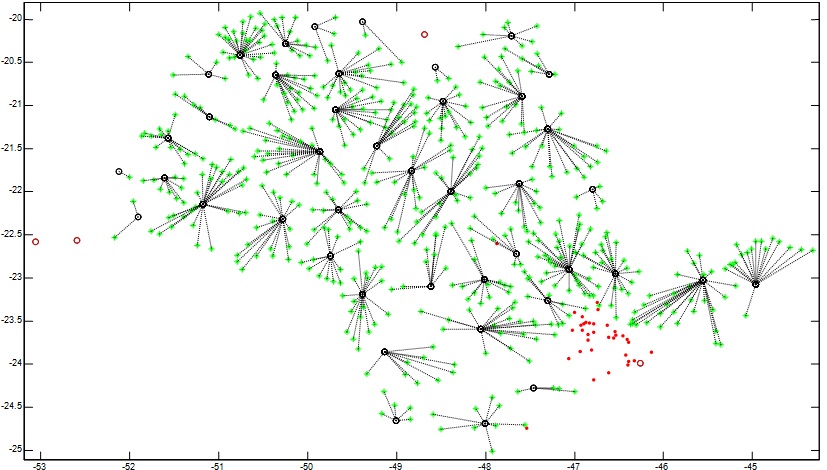
Fonte:
Autores.
Com base nestes grupos foram realizados os estudos sobre os coeficientes de correlação entre as variáveis identificadas conforme ilustrado nas figuras 5 a 11:
Figura 5. Peso e Diâmetro do Grupo.

Fonte:
Autores
A equação da reta de regressão pelo método dos mínimos quadrados para esta análise é:
y=0.00044125 x + 43.9543
O coeficiente de correlação foi de 0.47, segundo Karl Pearson houve uma correlação linear moderada entre os dados, mostrando estatisticamente que os dados (Diâmetro do grupo) tem uma relação moderada em função dos dados (Peso do grupo).
O valor do R2 foi de 0.23 mostrando que 23% da variância dos dados (Diâmetro do grupo) é explicada pela variância dos dados (Peso do grupo).
Figura 6. Peso do Grupo e Distância entre o centróide e a capital do estado.

Fonte:
Autores
A equação da reta de regressão obtida pelo método dos mínimos quadrados é:
y =-7.9004e-006 x + 3.2797
O coeficiente de correlação foi de -0.12, segundo Karl Pearson houve uma correlação linear fraca negativa entre os dados, mostrando estatisticamente que os dados (Distância da capital) tem uma relação fraca em função dos dados (Peso do grupo).
O valor do R2 foi de 0.015 mostrando que 1.5% da variância dos dados (Distância da capital) é explicada pela variância dos dados (Peso do grupo).
Figura 7. Peso do Grupo e do Centróide.

Fonte:
Autores.
A equação da reta de regressão obtida pelo método dos mínimos quadrados é:
y =0.16505 x + 2219.7371
O coeficiente de correlação foi de 0.84, segundo Karl Pearson houve uma correlação linear fortemente positiva entre os dados, mostrando estatisticamente que os dados (Peso do centroide) tem uma relação forte em função dos dados (Peso do grupo).
O valor do R2 foi de 0.71 mostrando que 71% da variância dos dados (Peso do centroide) é explicada pela variância dos dados (Peso do grupo).
Figura 8. Diâmetro do Grupo e Distância entre o centróide e a capital do estado.

Fonte:
Autores.
A equação da reta de regressão obtida pelo método dos mínimos quadrados é:
y = -2.3713 x + 4.4025
O coeficiente de correlação foi de -0.34, segundo Karl Pearson houve uma correlação linear moderada negativa entre os dados, mostrando estatisticamente que os dados (Distância da capital) tem uma relação fraca em função dos dados (Diâmetro do grupo).
O valor do R2 foi de 0.12 mostrando que 12% da variância dos dados (Distância da capital) é explicada pela variância dos dados (Diâmetro do grupo).
Figura 9. Distância entre o centróide e a capital do estado e o Peso do Centróide.

Fonte:
Autores.
A equação da reta de regressão obtida pelo método dos mínimos quadrados é:
y = -2.3713 x + 4.4025
O coeficiente de correlação foi de -0.053, segundo Karl Pearson houve uma correlação linear fraca negativa entre os dados, mostrando estatisticamente que os dados (Peso do centróide) tem uma relação fraca em função dos dados (Distância da capital).
O valor do R2 foi de 0.003 mostrando que 0.3% da variância dos dados (Peso do centróide) é explicada pela variância dos dados (Distância da capital).
Figura 10. Diâmetro do Grupo e Peso do Centróide.
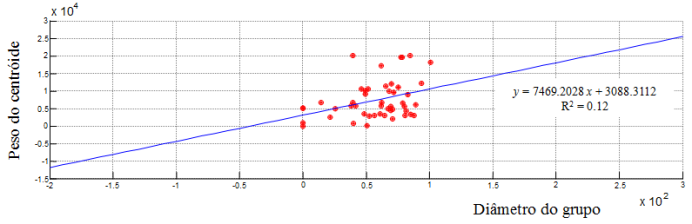
Fonte:
Autores.
A equação da reta de regressão obtida pelo método dos mínimos quadrados é:
y = 7469.2028 x + 3088.3112
O coeficiente de correlação foi de 0.35, segundo Karl Pearson houve uma correlação linear moderada positiva entre os dados, mostrando estatisticamente que os dados (Peso do centróide) tem uma relação moderada em função dos dados (Diâmetro do grupo).
O valor do R2 foi de 0.12 mostrando que 12% da variância dos dados (Peso do centróide) é explicada pela variância dos dados (Diâmetro do grupo).
Figura 11. Número de elementos do grupo e Peso do centróide.

Fonte:
Autores.
A equação da reta de regressão obtida pelo método dos mínimos quadrados é:
y = 293.6928 x + 3460.6905
O coeficiente de correlação foi de 0.47, segundo Karl Pearson houve uma correlação linear moderada positiva entre os dados, mostrando estatisticamente que os dados (Peso do centróide) tem uma relação moderada em função dos dados (Número de elementos do grupo).
O valor do R2 foi de 0.22 mostrando que 22% da variância dos dados (Peso do centróide) é explicada pela variância dos dados (Número de elementos do grupo).
Os dados resultantes destes coeficientes de correlação podem ser observados de forma sintética no quadro 2.
Quadro 2. Coeficientes de correlação segundo Karl Pearson

Fonte:
Autores.
Observa-se que o Peso do centróide em função do Peso do grupo apresenta o maior coeficiente de correlação, 0.84, ou seja, uma correlação linear forte entre os dados.
Aplicou-se, também, o coeficiente de correlação de postos de Spearman (PAGANO & GAUVREAU, 2012):

onde:
ρ é o coeficiente de correlação de postos de Spearman,
di é a diferença entre cada posto de valor correspondentes de x e y, e
n é o número dos pares dos valores (elementos).
Uma outra informação obtida nesta análise foi o P valor que:
“A probabilidade de obtermos uma média tão ou mais extrema do que a média da amostra observada, dado que a hipótese nula é verdadeira, é chamada de p-valor do teste ou simplesmente p” (PAGANO & GAUVREAU, 2012).
O quadro 3 apresenta os resultados dos coeficientes de postos de Spearman para as mesmas análises feitas com base no coeficiente de correlação de Pearson. Foram obtidos os valores do coeficiente de correlação e o valor de P (P valor) para n igual a 48 grupos identificados no processamento.
Quadro 3. Coeficientes de correlação de postos de Spearman
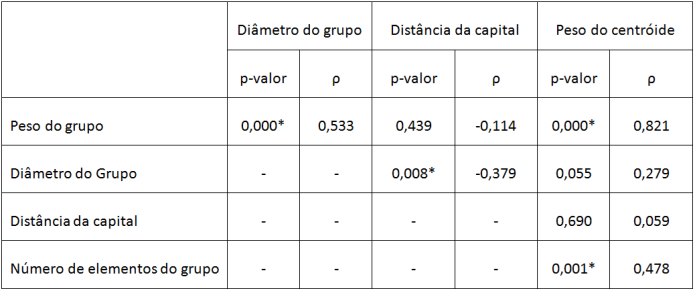
Fonte:
Autores.
* Correlação é significante para o nível de 0.01 (bicaudal).
Observa-se no quadro 3 que o p-valor na maior parte das análises foi inferior a 5% de tolerância, ou seja, com um nível de confiança de 95% (Bicaudal), mostrando que houve uma correlação entre os dados de x e y.
Mais importante do que a interpretação destes dados o que se procurou demonstrar foi a existência de grande variedade de possibilidades de análise sobre dados que já estão disponíveis e que podem ser de grande valia para as mais diversas necessidades de setores da economia e da sociedade em geral.
À Ciência da Informação cabe o papel de ampliar as possibilidades de acesso aos conhecimentos específicos para que o grande volume de dados já disponíveis na Internet possam contribuir, de forma efetiva, para redução da assimetria informacional ainda presente em grande parte das relações entre os mais diversos setores do tecido social.
Informações para uso dos dados
• Resumo • Introdução • Métodos • Resultados • Informações para uso dos dados • Informações Adicionais • Referências • Citação dos Dados • Informações sobre os Autores • Informações Complementares
Os dados disponibilizados (Sant’Ana e Bonini Neto, 2014) estão estruturados no formato CSV e contendo em cada linha os atributos:
[1] codigo: código da cidade;
[2] dist_centro: distância em quilômetros entre a cidade e o centro do grupo;
[3] nome: nome da cidade;
[4] longitude: coordenada longitude da cidade;
[5] latitude: coordenada latitude da cidade;
[6] peso: número de animais em ordenha na cidade;
[7] dist_cap: distancia em quilômetros entre a cidade e a capital do estado;
[8] id_centro: chave primária da cidade identificada como centro do grupo;
[9] id_cidade: chave primária da cidade;
• Resumo • Introdução • Métodos • Resultados • Informações para uso dos dados • Informações Adicionais • Referências • Citação dos Dados • Informações sobre os Autores • Informações Complementares
Como citar este artigo
SANT’ANA, R.C.G.; BONINI NETO, A. Análise de dados sobre produção de leite: uma perspectiva da Ciência da Informação. Informação e Tecnologia. V.1,Num.1, jan/jun, 2014
• Resumo • Introdução • Métodos • Resultados • Informações para uso dos dados • Informações Adicionais • Referências • Citação dos Dados • Informações sobre os Autores • Informações Complementares
AKERLOF, G.A. The Market for “Lemons”: Quality Uncertainly and the Market Mechanism. In: The Quarterly Journal of Economics, MIT Press, Vol. 84, Nº 3, Agosto 1970. Pp. 488-500.
CASTELLS, Manuel. A sociedade em rede. v.1. São Paulo: Paz e Terra, 1999.
CARDOSO, L.V.; NOGUEIRA,R.J.; VERCESI FILHO,A.E.; EL FARO, L.; LIMA,N.C. Objetivos de Seleção e Valores Econômicos de Características de Importância Econômica para um Sistema de Produção de Leite a Pasto na Região Sudeste. Revista Brasileira de Zootecnia, v.33, n.2, p.320-327, 2004
CONESA, F. M. Derecho a la intimidad y estado de derecho. Universidad de Valencia, 1984. 102 páginas.
FONSECA,L.F.L. Critérios no pagamento por qualidade.Revista Balde Branco, v.37, n.444, p.28-34, 2001
LEWIS K.A., NEWBOLD M.J., TZILIVAKIS, J. Developing an emissions inventory from farm data. Journal of Environmental Management. 55, 183-197. 1999
PAGANO, M.; GAUVREAU, K. Princípios de Bioestatística. São Paulo: Cengage Learning, 2012.
SANT’ANA, R. C. G. Ciclo de Vida dos Dados e o papel da Ciência da Informação. In: XIV Encontro Nacional de Pesquisa em Ciência da Informação, 2013, Florianópolis / SC. Anais do XIV Encontro Nacional de Pesquisa em Ciência da Informação, 2013. Disponível em <http://enancib.sites.ufsc.br/index.php/enancib2013/XIVenancib/paper/viewFile/284/319>
STANTON, J. M. (2001), Galton, Pearson, and the peas: A brief history of linear regression for statistics instructors. Journal of Statistical Education, 9,3. Disponível em: <http://www.amstat.org/publications/JSE/v9n3/stanton.html>
• Resumo • Introdução • Métodos • Resultados • Informações para uso dos dados • Informações Adicionais • Referências • Citação dos Dados • Informações sobre os Autores • Informações Complementares
IPEA Instituto de Pesquisa Econômica Aplicada. Ipeadata. Disponível em: <http://www.ipeadata.gov.br>. Acessado em março de 2014.
SANT’ANA, R.C.G.; BONINI NETO A. Cidades e Animais em Ordenha. Informação e Tecnologia. V.1,Num.1, jan/jun, 2014. Disponível em: <http://periodicos.ufpb.br/ojs2/public/imagens/itec/SantAnaBonini_2014.csv>.
• Resumo • Introdução • Métodos • Resultados • Informações para uso dos dados • Informações Adicionais • Referências • Citação dos Dados • Informações sobre os Autores • Informações Complementares
Ricardo César Gonçalves Sant’Ana
Programa
de Pós-Graduação em Ciência da Informação - UNESP,
Universidade Estadual Paulista UNESP, São Paulo,
Brasil.
ricardosantana@marilia.unesp.br
Alfredo Bonini Neto
Coordenadoria
de Curso de Engenharia de Biosistemas, Universidade Estadual
Paulista UNESP, São Paulo, Brasil.